
大众点评美食——字体字典生成(二)
紧接上篇介绍了字体加密中字体文件和页面源码中的对应关系,要获取数据 你还需要一份字典!
pycharm一开 一顿操作猛如虎
1.获取页面源码 并提取css的链接

2.下载其中的四个类型标签对应的woff文件
打开来康康


两个文件里面的字体竟然是一样的,只有编码不同,也就是说加密的字体只有这600多个
3.直接的woff文件python不好操作,先用fontTools转为xml文件
from fontTools.ttLib import TTFontfont = TTFont('./font_files/' + woff_file_name + '.woff') font.saveXML('./font_files/' + woff_file_name + '.xml')
随便开一个xml看一下

GlyphID 标签的name就是编码(GlyphID 的顺序和woff文件里面你看字体的顺序是一样的)

TTGlyph标签就是每个字体的样式(需要注意的是这个顺序和GlyphID的顺序不同,只能通过name来对应回去)
4.真实文本的获取
python解析一下xml文件把全部编码拿出来
![]()
写一个简单的vue用同样的操作渲染出全部字体 然后百度识图送检一波 (对于规整的字形准确率100%
然后你就拿到所有的python能识别的文字了!!
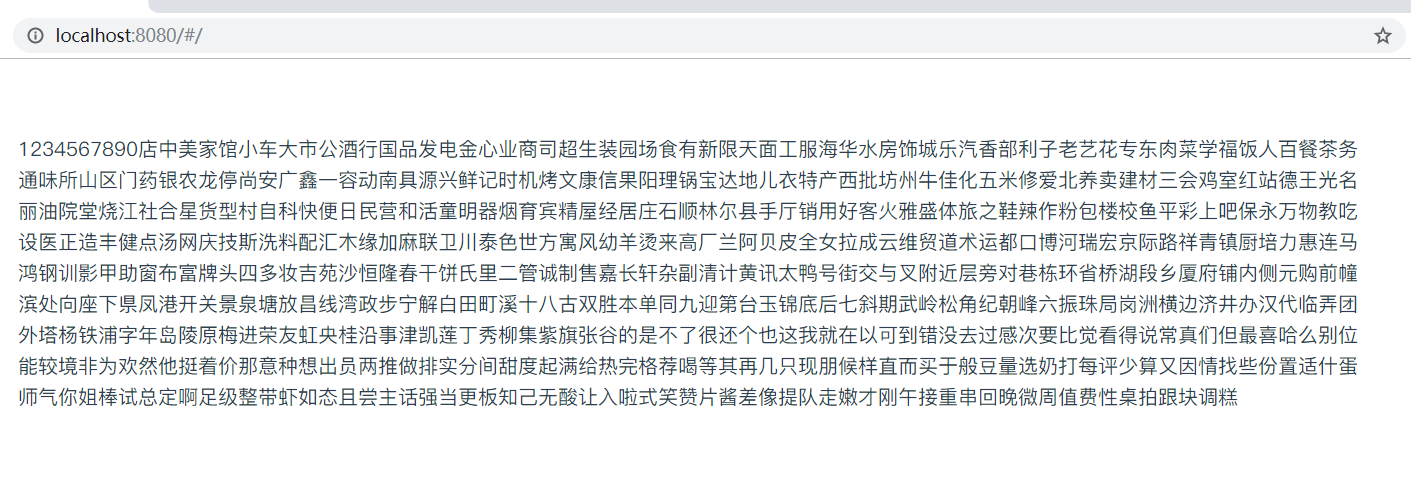
现在你有三份资料:
partA:GlyphID 标签的name中的编码
partB:TTGlyph标签的所有内容
partC:百度识图出来和GlyphID 标签的name中的编码顺序一致的文本
事实上当前页面已经解析完了,编码和文本对应成功,写一个字典对应即可,但是大众点评的不是每天都用同一套woff(每套woff里面的编码不同),所以为了可持续发展,在有需要时可以快速构建编码和文本对应的新字典,你还需要对partB下手,partB和partA可以映射,partA和partC可以映射,所以C和B可映射,partB(字形)每次都是不变的,文本也是不变的,最终你构建的是字形和文本的对应,这使你在编码变更时能快速获得最新的 编码和文本对应的新字典。
5.字形和文本的对应以及入库
先用现有明确编码将字形和文本对应
对字形对应文本进行md5编码在对应文本入库(md5前要删除name属性中的文本)

入库成功(字形md5以及对应文字)
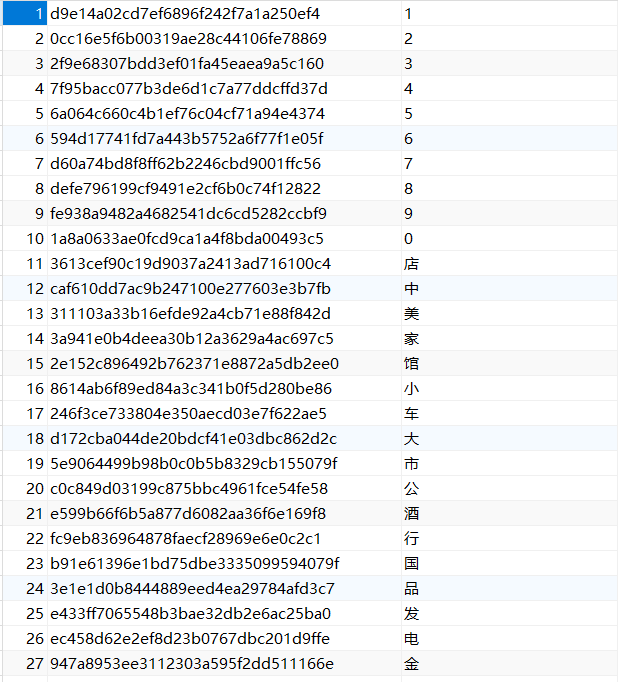
再写一个读数据库 根据 字形md5-文本 生成 编码-文本 字典的生成

拿着新字典测试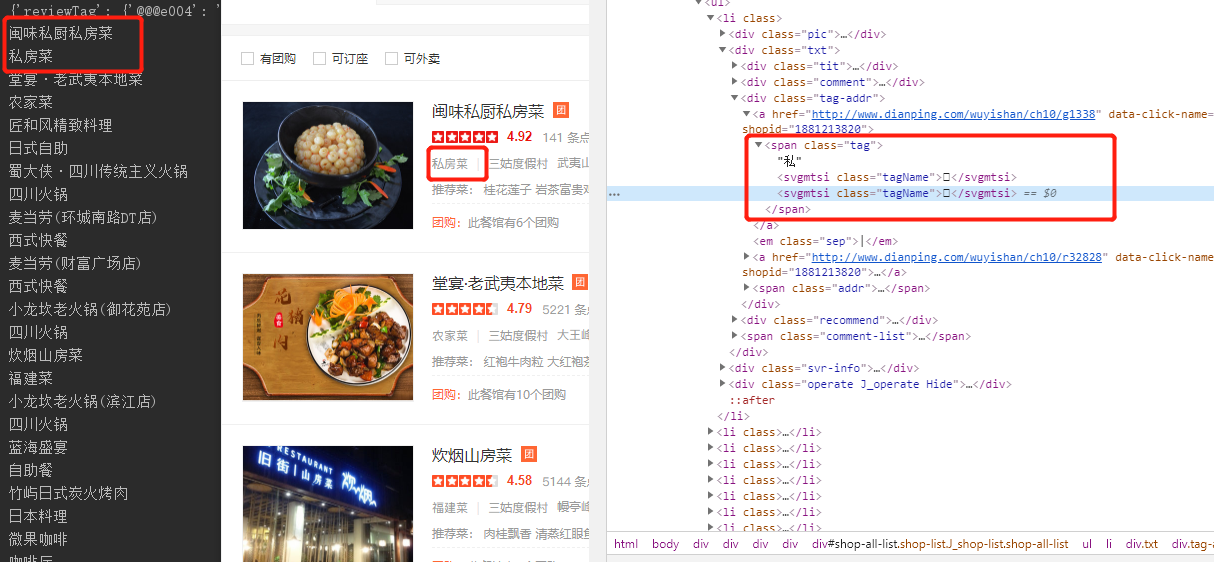
对应成功合影留念~
其他更细的处理细节就不一一说了 源码放一份在github 有需要可以自行获取!
哈哈哈哈
mark