
某团商铺查询 token参数解析与生成
一、分析接口
Network中可以找到返回是json格式数据的查询接口。
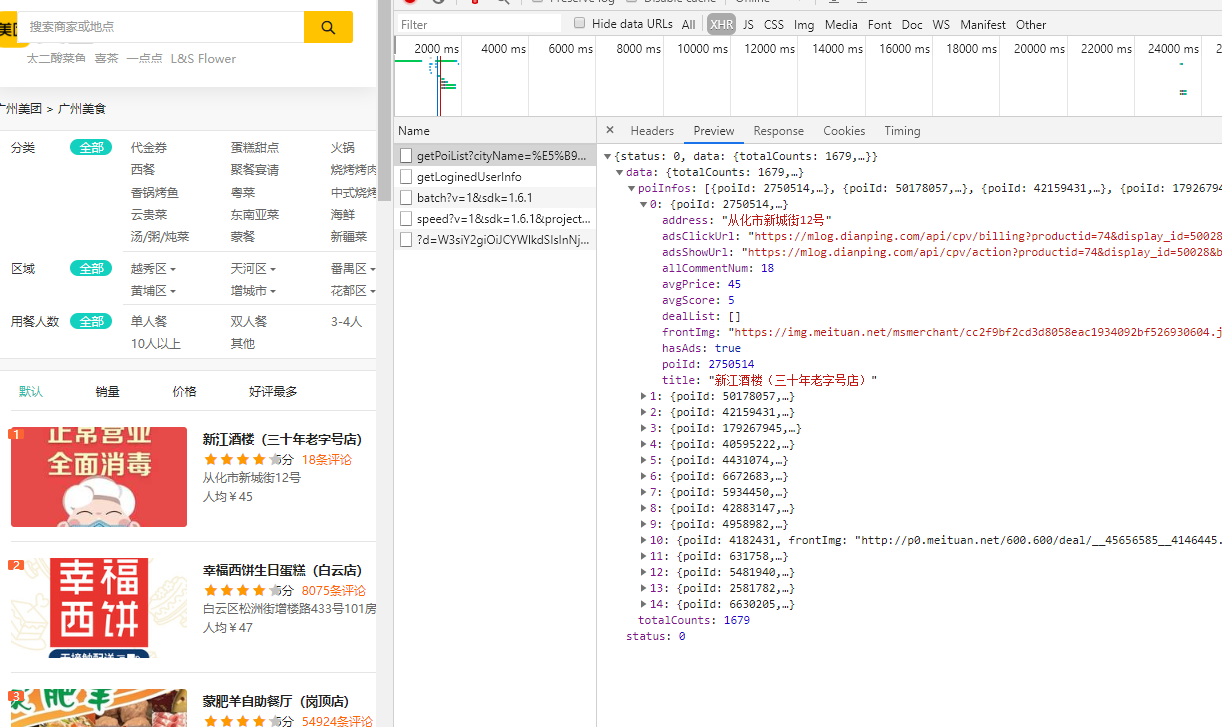
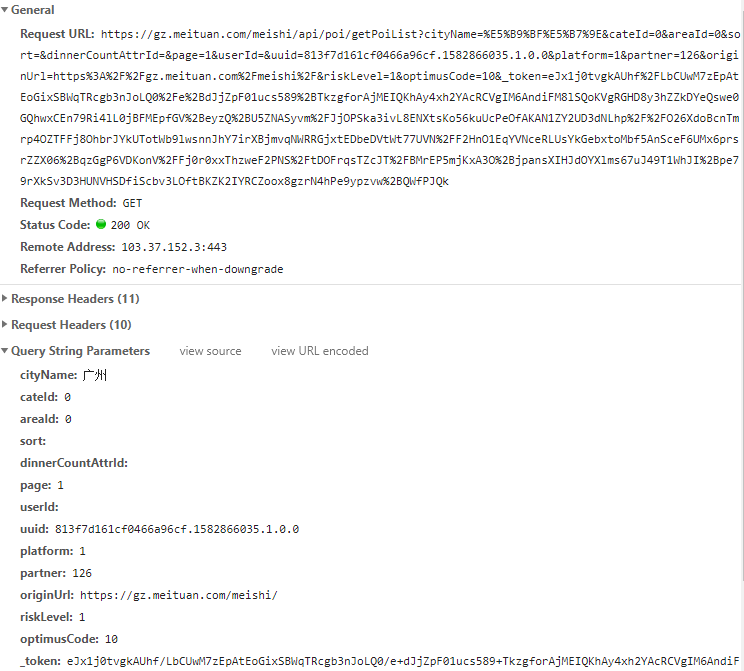
请求url中可以观察到请求的参数如下
二、token参数解析
首先看下token长什么样子
eJx1j0tvgkAUhf/LbCUwM7zEpAtEoGixSBWqTRcgb3nJoLQ0/e+dJjZpF01ucs589+TkzgforAjMEIQKhAy4xh2YAcRCVgIM6AndiFM8lSQoKVgRGHD8y3hZZkDYeQswe0GQhwxCEn79Ri4lL0jBFMEpfGV+eyzQ+U5ZNASyvm/JjOPSka3ivL8ENXtsKo56kuUcPeOfAKAN1ZY2UD3dNLhp//O26XdoBcnTmrp4OZTFFj8OhbrJYkUTotWb9lwsnnJhY7irXBjmvqNWRRGjxtEDbeDVtWt77UVN/F2HnO1EqYVNceRLUsYkGebxtoMbf5AnSceF6UMx6prsrZZX06+qzGgP6VDKonV/Fj0r0xxThzweF2PNS/tDOFrqsTZcJT/BMrEP5mjKxA3O+jpansXIHJdOYXlms67uJ49T1WhJI+pe79rXkSv3D3HUNVHSDfiScbv3LOftBKZK2IYRCZoox8gzrN4hPe9ypzvw+QWfPJQk
一眼看上去有点像base64编码,先用base64解析一下试试
import base64
s = 'eJx1j0tvgkAUhf/LbCUwM7zEpAtEoGixSBWqTRcgb3nJoLQ0/e+dJjZpF01ucs589+TkzgforAjMEIQKhAy4xh2YAcRCVgIM6AndiFM8lSQoKVgRGHD8y3hZZkDYeQswe0GQhwxCEn79Ri4lL0jBFMEpfGV+eyzQ+U5ZNASyvm/JjOPSka3ivL8ENXtsKo56kuUcPeOfAKAN1ZY2UD3dNLhp//O26XdoBcnTmrp4OZTFFj8OhbrJYkUTotWb9lwsnnJhY7irXBjmvqNWRRGjxtEDbeDVtWt77UVN/F2HnO1EqYVNceRLUsYkGebxtoMbf5AnSceF6UMx6prsrZZX06+qzGgP6VDKonV/Fj0r0xxThzweF2PNS/tDOFrqsTZcJT/BMrEP5mjKxA3O+jpansXIHJdOYXlms67uJ49T1WhJI+pe79rXkSv3D3HUNVHSDfiScbv3LOftBKZK2IYRCZoox8gzrN4hPe9ypzvw+QWfPJQk'
print(s)
result = base64.b64decode(s)
print(result)

先试下decode为utf-8,报错 无法直接解析,可能是经过压缩,尝试解压
import zlib
result2 = zlib.decompress(result)
print(result2)
结果如下
b'{"rId":100900,"ver":"1.0.6","ts":1582866069294,"cts":1582866069377,"brVD":[1030,1162],"brR":[[1920,1080],[1920,1080],24,24],"bI":["https://gz.meituan.com/meishi/","https://gz.meituan.com/"],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwljT2OwjAQhe9C4dKxCXjDSi4QFRKi4wBWPAmjje1oPEaCw3ANRMVpuAfWUr1PT+9n4Qjc3lslesfwBeTr0QWw7+fr/bgLjzEC7VKJvGWmmhFpZgwl75IHq5VIhCPGE032zDzn36YZbzIAcnFR9ik0lfMZGzG7sRaqENdJq5dGzJPjIVGoNmH+O8AFpso5EVtRMvz/lYLedrodfrw2uh/Uyhi3Mf0g9bpbdsaodi21VFItPst3R/k="}'
基本能看懂了大部分参数,ts 和 cts 是时间戳,注意位数 ts为时间戳*1000左右,cts比ts稍微大一些,其他参数为常量 sign用同样的方法尝试解析
sign = 'eJwljT2OwjAQhe9C4dKxCXjDSi4QFRKi4wBWPAmjje1oPEaCw3ANRMVpuAfWUr1PT+9n4Qjc3lslesfwBeTr0QWw7+fr/bgLjzEC7VKJvGWmmhFpZgwl75IHq5VIhCPGE032zDzn36YZbzIAcnFR9ik0lfMZGzG7sRaqENdJq5dGzJPjIVGoNmH+O8AFpso5EVtRMvz/lYLedrodfrw2uh/Uyhi3Mf0g9bpbdsaodi21VFItPst3R/k='
result3 = zlib.decompress(base64.b64decode(sign))
print(result3)
结果为一系列参数拼接:
b'"areaId=0&cateId=0&cityName=\xe5\xb9\xbf\xe5\xb7\x9e&dinnerCountAttrId=&optimusCode=10&originUrl=https://gz.meituan.com/meishi/&page=1&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=813f7d161cf0466a96cf.1582866035.1.0.0"'
三、尝试构造Token完成请求
大概就是一波反向操作,其中需要注意几个问题 sign中参数最后需要转化为字符串类型而非b
import base64
import zlib
import time
import requests
from urllib import parse
def decode_token(s):
a = base64.b64decode(s)
print(a)
result = zlib.decompress(a)
return result
def encode_sign(sign):
result = base64.b64encode(zlib.compress(sign))
return str(result, 'utf-8')
def encode_token():
d = {}
d["rId"] = 100900
d["ver"] = "1.0.6"
d["ts"] = int(time.time() * 1000)
# d["ts"] = 1582704455270
d["cts"] = int(time.time() * 1000 + 75)
# d["cts"] = 1582704455345
d["brVD"] = [822, 1151]
d["brR"] = [[1920, 1080], [1920, 1080], 24, 24]
d["bI"] = ["https://gz.meituan.com/meishi/", "https://gz.meituan.com/"]
d["mT"] = []
d["kT"] = []
d["aT"] = []
d["tT"] = []
d["aM"] = ""
sign = b'"areaId=0&cateId=0&cityName=\xe5\xb9\xbf\xe5\xb7\x9e&dinnerCountAttrId=&optimusCode=10&originUrl=https://gz.meituan.com/meishi/&page=1&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=27feb019adbd4186a43e.1582704408.1.0.0"'
d["sign"] = encode_sign(sign)
return d
def get_token():
d = encode_token()
data = str(d).replace("'", '"').replace(' ', '').encode()
# 进行 url 编码
token = parse.quote(encode_sign(data))
return token
if __name__ == '__main__':
token = get_token()
url = 'https://gz.meituan.com/meishi/api/poi/getPoiList?cityName=%E5%B9%BF%E5%B7%9E&cateId=0&areaId=0&sort=&dinnerCountAttrId=&page=1&userId=&uuid=27feb019adbd4186a43e.1582704408.1.0.0&platform=1&partner=126&originUrl=https%3A%2F%2Fgz.meituan.com%2Fmeishi%2F&riskLevel=1&optimusCode=10&_token=' + token
headers = {
# 'Cookie': '_lxsdk_cuid=17061bdb99fc8-02d1bc12d68259-3c604504-1fa400-17061bdb99fc8; _hc.v=4c9bb6b2-be41-8c38-5b85-55b5e525029d.1582187854; iuuid=F27BCC814DA3D3DE87F8AF31680A50D3481F769B5E586743E973F4D665CA8F1A; cityname=%E5%B9%BF%E5%B7%9E; _lxsdk=F27BCC814DA3D3DE87F8AF31680A50D3481F769B5E586743E973F4D665CA8F1A; webp=1; latlng=23.130873,113.314218,1582596340177; i_extend=C_b1Gimthomepagecategory11H__a; PHPSESSID=glju3e7tram9mm14oi6gl8pdq2; Hm_lvt_f66b37722f586a240d4621318a5a6ebe=1582704399; Hm_lpvt_f66b37722f586a240d4621318a5a6ebe=1582704399; __utma=211559370.1822528469.1582704399.1582704399.1582704399.1; __utmc=211559370; __utmz=211559370.1582704399.1.1.utmcsr=baidu|utmccn=baidu|utmcmd=organic|utmcct=zt_search; uuid=27feb019adbd4186a43e.1582704408.1.0.0; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; ci=20; __mta=209023277.1582187792859.1582187792859.1582704411604.2; client-id=50dea765-bdec-4ac7-b5b4-5f92afa9f54c; _lxsdk_s=17080d79353-d36-553-5%7C%7C4',
'Host': 'gz.meituan.com',
'Referer': 'https://gz.meituan.com/meishi/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
}
r = requests.get(url, headers=headers)
print(r.text)
结果:

目前店铺页数据提取比较普通 这里不多赘述。观察发现,数据中显示totalCounts有以前多条,但是实际上用浏览器操作的过程中只有67页的数据,所以如果想要获得完整的数据,细分区域,分类这些参数,通过排列组合分次请求才能获得更多数据。
yibing
太赞了!!!看了你的帖子终于爬成功了!!!感谢!
KaGen
诶嘿!不客气
十叁
KaGen
stephengbc
想问下大佬我这里返回显示未登录具体可以怎么解决呀 感恩!!!
感恩!!!
KaGen
检查下是不是没有携带cookie进行访问哈?邮箱有点东西哈哈哈哈哈
KaGen
我提供的cookie可能已经过期,你需要用你自己的cookie进行访问
stephengbc
哈哈哈哈,非常感谢您的回复~但是我在想一直使用自己的cookie应该会被识别到在爬然后被封号吧?使用timesleep间隔爬的话可以避免被封号吗,或者我也看到有人仿造cookie。因为我要爬不同区域的商家数据,加起来可能有好几百页,我觉得大概率会遇到反爬,您当时是没有遇到封ip这种反爬吗?
KaGen
timesleep可以控制访问速度 几百页数据不多 控制速度不会那么容易被封
stephengbc
ok,那我设置时间长些,再次感谢~
stephengbc
您回复的好快,感动!最近急需爬他们的数据,所以可能问题有点多,实在抱歉,耽误您时间了哈哈哈
guoke
留个爪,一起玩,我也在整
二五灵灵八四七七零四
KaGen
测试邮件
LL
大神,大众点评滑块验证的_token和behavior可以请教下你么
KaGen
emmmm 这个我也没有探究过 可能帮不上忙啦